Bất cứ doanh nghiệp hay tập đoàn nào cũng có cho một kho dữ liệu khổng lồ. Kho dữ liệu vô cùng quan trọng bởi nó là mọi thông tin liên quan đến doanh nghiệp, khách hàng và đối tác. Vậy kho dữ liệu có vai trò như thế nào trong hệ thống Business Intelligence (BI). Cùng tìm hiểu bài viết này để giúp bạn hiểu được vai trò quan trọng của kho dữ liệu nhé.
1. Vai trò của Kho dữ liệu trong hệ thống BI
Hệ thống thông tin quản trị thông minh (Business Intelligence – BI) là một hệ thống giúp các nhà quản lý công cụ và một phương pháp mới điều hành doanh nghiệp như đã trình bày trong bài trước. Để có thể trình bày được thông tin trên các báo cáo quản trị (dashboard) thì cần có nguồn cung cấp thông tin đó – đó chính là Kho dữ liệu (Data warehouse). Vị trí của Kho dữ liệu được minh họa ở Figure 1.
Phía bên phải (hình oval bên phải) là đối tượng thụ hưởng của hệ thống – những người sẽ phân tích thông tin để đưa ra các kế hoạch dài hạn hay điều hành ngắn hạn.
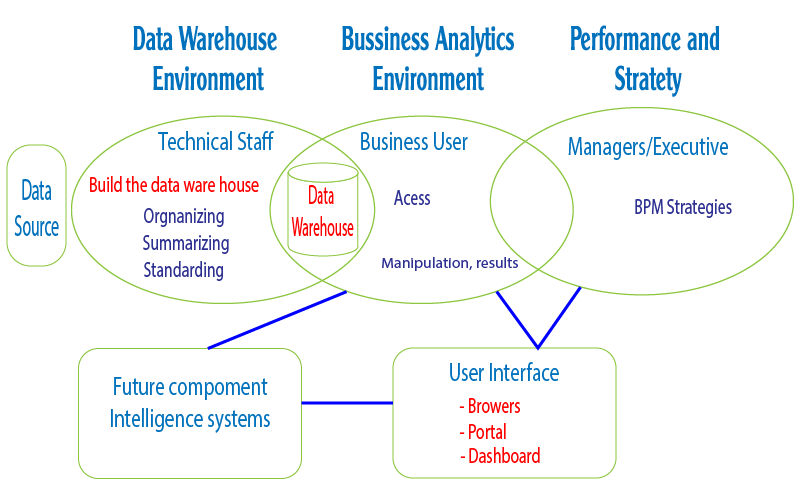
Để có thể đưa ra được các thông tin có tính hệ thống, phù hợp với nghiệp vụ kinh doanh của doanh nghiệp thì cần có đội ngũ nghiệp vụ (hình oval ở giữa), chịu trách nhiệm xây dựng các báo cáo quản trị từ Kho dữ liệu. Cuối cùng để có thể lấy được dữ liệu và đưa vào Kho dữ liệu theo nhu cầu nghiệp vụ thì cần có đội ngũ kỹ thuật (hình oval bên trái).
Ngoài ra có thể có các hệ thống thông mình (hình vuông góc dưới bên trái) có thể khai thác dữ liệu từ Kho dữ liệu nhằm hỗ trợ quản lý ra quyết định.
2. Định nghĩa Kho dữ liệu
Kho dữ liệu ban đầu được định nghĩa là một tập dữ liệu được dùng để hỗ trợ quy trình ra quyết định. Theo quá trình phát triển, Kho dữ liệu được định nghĩa là một môi trường thông tin (information environment) (từ môi trường thông tin thể hiện nó không phải là một sản phẩm (product)), có các chức năng:
Cung cấp một góc nhìn toàn diện về doanh nghiệp:
Cho dù doanh nghiệp có nhiều mảng kinh doanh được quản lý bởi các hệ thống tác nghiệp khác nhau, nhưng Kho dữ liệu là nơi đã tập hợp (tích hợp) được mọi thông tin về các mảng nghiệp vụ khác nhau để cung cấp một góc nhìn toàn diện. Việc tích hợp này còn cung cấp khả năng đánh giá chéo các mảng nghiệp vụ khác nhau để đánh giá sự tương quan giữa chúng.
Cung cấp đầy đủ thông tin hiện tại và lịch sử của doanh nghiệp, và sẵn sàng cho việc khai thác, sử dụng cho việc hỗ trợ ra quyết định chiến lược.
Từ thông tin ở đây thể hiện dữ liệu ở trong kho không chỉ đơn thuần là dữ liệu thô lấy từ các hệ thống tác nghiệp mà nó đã được tổng hợp, tính toán thành các độ đo có ý nghĩa phân tích.
Có khả năng cung cấp dữ liệu chi tiết theo nhu cầu mà không phải truy xuất các hệ thống tác nghiệp:
Điều này thể hiện trong một số trường hợp có thể nhu cầu phân tích dữ liệu ở mức giao dịch, thì nó cũng sẽ được lưu sẵn ở Kho dữ liệu.
Đảm bảo thông tin trong Kho dữ liệu có tính nhất quán:
Ví dụ doanh nghiệp có nhiều nghiệp vụ được quản lý với các hệ thống tác nghiệp khác nhau, nhưng cần đảm bảo ánh xạ được một khách hàng xuất hiện ở nhiều hệ thống về 1 người duy nhất. Điều này áp dụng cho các đối tượng dữ liệu khác.
Ngoài ra một trường dữ liệu có thể được biểu diễn bằng nhiều cách khác nhau, ví dụ Tên khách hàng có hệ thống tách họ và tên thành 2 trường khác nhau, có hệ thống chỉ lưu trong 1 trường. Khi tổng hợp về Kho dữ liệu thì sẽ được chuyển về 1 dạng thống nhất.
Là nguồn thông tin chiến lược mềm dẻo và có tính tương tác:
Chữ mềm dẻo và tương tác ở đây thể hiện người dùng có thể lấy các thông tin khác nhau của cùng một đối tượng. Từ tương tác ở đây thể hiện có thể thực hiện được nhiều thao tác với các đối tượng dữ liệu thay vì trả lại một danh sách tĩnh.
Ví dụ có thể lấy dữ liệu tổng hợp theo ngày, theo tuần, theo tháng của cùng 1 đối tượng dữ liệu. Tính tương tác thể hiện người dùng có thể áp dụng các thao tác phân tích dữ liệu, một ví dụ là nền tảng phân tích dữ liệu SQL Server Analysis Services (SSAS) cho phép người dùng có thể tương tác để phân tích dữ liệu.
3. Đặc điểm của Kho dữ liệu
Dữ liệu được lưu trong Kho dữ liệu không được tạo ra trực tiếp từ người dùng mà được lấy từ các nguồn dữ liệu sẵn có và mục đích là phục vụ tạo ra các báo cáo quản trị do đó nó có các tính chất sau:
Hướng chủ đề (subject-oriented)
Mục đích của Kho dữ liệu là phục vụ các yêu cầu phân tích, hoặc khai phá cụ thể được gọi là chủ đề. Ví dụ với chủ đề phân tích nhân sự thì có thể bao gồm các độ đo về doanh thu của từng người, số ngày nghỉ trong tháng, số dự án tham gia trong tháng, theo các chiều phân tích: thời gian, chi nhánh, sản phẩm, …
Một sự so sánh dễ hiểu, giống như chẩn đoán một bệnh ví dụ bệnh liên quan đến tim, thì bác sỹ cần quan tâm không chỉ một mà một vài chỉ số như các chỉ số liên quan đến máu, chỉ số về huyết áp, nhịp tim, điện tâm đồ. Ngoài ra còn cần theo dõi theo thời gian (có thể là hàng ngày) để xem xét sự thay đổi mà có phương pháp điều trị kịp thời.
Trong trường hợp này thời gian được gọi là chiều phân tích. Để chẩn đoán được chính xác thì cần đầy đủ các thông tin về các chỉ số trên, và cũng không cần các chỉ số khác lẫn vào làm nhiễu quá trình chẩn đoán và cũng không cần thiết. Việc tổ chức dữ liệu theo chủ đề này sẽ dẫn đến nhu cầu tổ chức lưu trữ dữ liệu khác với các cơ sở dữ liệu tác nghiệp.
Được tích hợp (integrated):
Tại một bệnh viện, các phòng khác nhau sẽ thực hiện các xét nghiệm khác nhau, do đó để có được đầy đủ thông tin phục vụ chẩn đoán thì cần thu thập được kết quả từ nhiêu nguồn. Điều này hoàn toàn tương tự như tại doanh nghiệp, dữ liệu cần để phân tích có thể nằm rải rác ở nhiều hệ thống tác nghiệp khác nhau, và vì vậy cần tích hợp lại. Quá trình tích hợp này sẽ được thực hiện trong quá trình ETL như đã trình bày ở bài trước.
Việc tổng hợp dữ liệu từ nhiều nguồn vào một kho dữ liệu cho phép chúng ta có thể xem đồng thời nhiều nhóm chỉ tiêu khác nhau (từ nhiều hệ thống nghiệp vụ khác nhau), ví dụ ta có thể xem chỉ tiêu doanh thu ở nhiều mảng nghiệp vụ khác nhau để có thể so sánh được sự tương quan giữa các mảng nghiệp vụ này. Điều này cũng giống trong chuẩn đoán bệnh ta có thể cần nhiều xét nghiệm (thử máu, thử nước tiếu, siêu âm, …) và kiểm tra khác nhau để có thể đưa ra kết luận chính xác.
Có gán nhãn thời gian (time variant):
Như đã đề cập, với các chỉ số thay đổi liên tục (như huyết áp, nhịp tim) việc chẩn đoán bệnh sẽ cần dữ liệu của các hôm trước để so sánh phục vụ quá trình điều trị. Do đó hàng ngày cần phải lưu lại giá trị của các chỉ số này. Hay nói cách khác các chỉ số này khi lưu sẽ được gán 1 nhãn thời gian tương ứng.
Tương tự như vậy, dữ liệu lịch sử có tầm quan trọng đặc biệt trong phân tích dữ liệu, cùng một độ đo sẽ có nhiều giá trị khác nhau trong lịch sử có thể dùng để so sánh với nhau để biết được sự thay đổi là tốt hay xấu.
Ví dụ, độ đo doanh thu của một mặt hàng của tháng hiện tại, nếu đem so sánh với doanh thu của mặt hàng đó trong tháng trước, tháng này năm trước thì sẽ có nhiều thông tin hơn để đánh giá doanh thu của mặt hàng đó là tốt hay không, trên cơ sở đó sẽ có các quyết định phù hợp. Ngoài ra, dữ liệu lịch sử còn cho phép dự báo được tương lai khi ứng dụng khai phá dữ liệu.
Bất biến (non-volatile):
Khác với các cơ sở dữ liệu (CSDL) giao dịch, nơi thông tin của một đối tượng có thể được cập nhật thay đổi hàng ngày, dữ liệu trong Kho dữ liệu có chức năng báo cáo lại các chỉ số về hoạt động kinh doanh thực tế đã xảy ra. Do đó dữ liệu trong Kho dữ liệu không thể cập nhật, thay đổi vì nó sẽ không phản ánh đúng thực tế. Do đó với kho dữ liệu chỉ có 2 thao tác chính là tải dữ liệu vào kho và truy cập (đọc) dữ liệu từ kho.
Trường hợp sau khi tổng hợp dữ liệu mà dữ liệu ở trong nguồn bị thay đổi, khi đó một giải pháp xử lý là thực hiện lại quá trình ETL để tải lại dữ liệu từ nguồn vào Kho dữ liệu chứ không cho phép sửa đổi dữ liệu ở trong Kho. Một ý nghĩa khác của tính chất này là dữ liệu lịch sử vẫn được bảo tồn, vẫn có ý nghĩa chứ không như dữ liệu tác nghiệp ở các cơ sở dữ liệu, dữ liệu cũ (năm trước, hoặc tháng trước) không có ý nghĩa phục vụ hoạt động hằng ngày.
Như vậy, nếu như CSDL tác nghiệp được ví như cái tủ sách cá nhân, nơi người ta thường xuyên tra cứu, cập nhật, hiệu đính, ghi chú vào lề, thêm mới hoặc chuyển sách đi. Thì Kho dữ liệu lại được so sánh với thư viện quốc gia, nơi các tài liệu kinh điển được đưa đến liên tục để lưu trữ và tham khảo, không ai sửa chữa hoặc chuyển chúng qua chỗ nào khác cả.
4. Mô hình biểu diễn dữ liệu trong Kho dữ liệu
Vì các đặc điểm dữ liệu được tổ chức hướng chủ đề, nên mô hình quan hệ thực thể được dùng trong thiết kế cơ sở dữ liệu (CSDL) tác nghiệp là không còn phù hợp. Trong thực tế, người ta dùng 2 khái niệm là độ đo (measure) và chiều phân tích (dimension) để biểu diễn dữ liệu trong kho. Áp dụng vào ví dụ ở trên, tập các chỉ số máu, nhịp tim, huyết áp sẽ tương ứng với các độ đo, và thời gian là chiều phân tích.
Một số mô hình sau đã được thiết kế để biểu diễn các độ đo và chiều phân tích. Người ta vẫn dùng mô hình cơ sở dữ liệu quan hệ để biểu diễn, trong đó bảng sự kiện (Fact) sẽ được tạo ra để chứa các độ đo, và bảng chiều (demension) được dùng để chứa thông tin về các chiều phân tích, bảng sự kiện sẽ có mối quan hệ với bảng chiều tương ứng. Cụ thể có 3 mô hình biểu diễn quan hệ giữa bảng sự kiện và bảng chiều như sau:
Mô hình ngôi sao (star schema)
Trong mô hình này, một bảng sự kiện sẽ nằm ở trung tâm và xung quanh là các bảng chiều (Figure 2 bên trái), vì hình ảnh này giống một ngôi sao đang phát sáng nên người ta đặt cho nó tên là mô hình ngôi sao (Figure 2 bên phải).
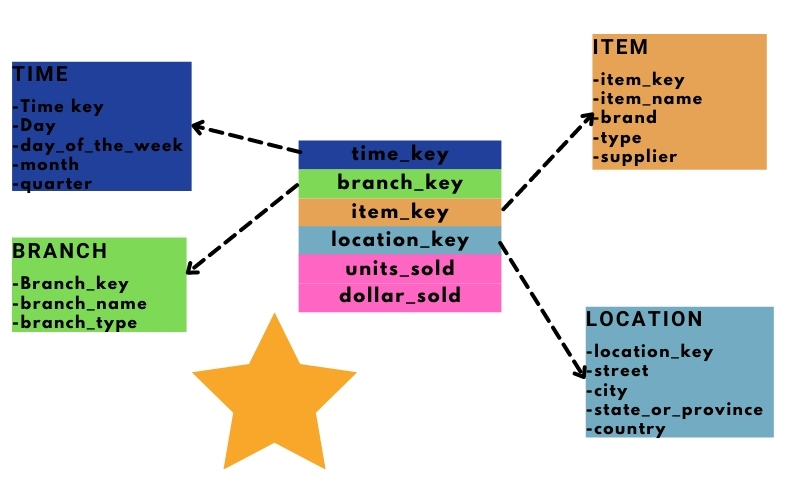
Ở trong ví dụ trong Figure 2, bảng sự kiện chứa thông tin bán hàng với các độ đo: số lượng bán được (unit sold), số tiền thu được (dollars sold) và trung bình doanh thu (average sale). Bảng sự kiện này có liên kết với 4 bảng chiều: thời gian (time), chi nhánh cửa hàng (branch), mặt hàng (item) và vị trí cửa hàng (location).
Đặc điểm của mô hình ngôi sao là chỉ có 1 cấp quan hệ giữa bảng chiều và bảng sự kiện do đó khi truy xuất dữ liệu thì các hệ quản trị CSDL sẽ xử lý nhanh hơn và trả lại kết quả nhanh hơn. Nhưng nhược điểm của phương pháp này là một số bảng chiều chưa được chuẩn hóa. Ví dụ như bảng chiều vị trí, trong đó nó không được chuẩn hóa theo mô hình cơ sở dữ liệu.
Trong bảng này nhiều dữ liệu bị lặp lại ví dụ toàn bộ các trường city, state_or_province, và country sẽ bị lặp trên các dòng có trùng city. Việc dữ liệu không được chuẩn hóa sẽ không đảm bảo được sự nhất quán về dữ liệu. Khi dữ liệu thay đổi ví dụ người ta đổi tên city, có thể quá trình cập nhật sẽ bị sót do rất nhiều dòng cần phải cập nhật. Ngoài ra dữ liệu lặp sẽ làm tăng không gian lưu trữ, ảnh hưởng đến tiến trình sao lưu, đồng bộ dữ liệu.
Một chủ đề phân tích có thể được biểu diễn bằng một hoặc nhiều “ngôi sao”.
Mô hình bông tuyết (snowflake)
Mô hình bông tuyết khắc phục nhược điểm của mô hình ngôi sao ở khía cạnh dữ liệu không được chuẩn hóa. Do đó nó cho phép các bảng chiều được chuẩn hóa (tùy theo trường hợp mà nó có thể chuẩn hóa đến chuẩn 3 Boyce–Codd). Vì sau khi chuẩn hóa các bảng chiều, nó có hình dạng giống một bông tuyết (Figure 3 bên phải), đây là lý do nó có tên như vậy.
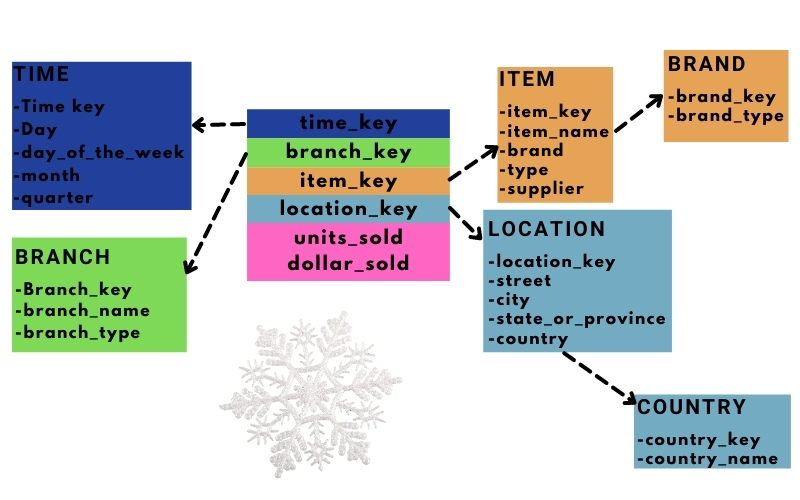
Figure 3 minh họa mô hình bông tuyết trong đó bảng location đã được chuẩn hóa, do thiếu không gian nên ở hình này chỉ vẽ được đến bảng city (trong đó có chứa khóa state_or_province_key) để liên kết với bảng state_or_province, tiếp tục bảng state_or_province lại có quan hệ với bảng country (nếu muốn chuẩn hóa đến chuẩn 3). Tuy nó khắc phục được nhược điểm của mô hình chòm sao, nhưng nó lại phá mất ưu điểm của mô hình ngôi sao là tốc độ xử lý dữ liệu khi nó phải liên kết nhiều bảng với nhau để lấy dữ liệu.
Tương tự với mô hình ngôi sao, một chủ đề phân tích có thể được biểu diễn bằng một hoặc một vài bông tuyết.
Mô hình chòm sao (constellation)
Mô hình chòm sao tiếp tục là sự mở rộng mô hình bông tuyết, trong đó nó cho phép các bảng sự kiện có thể sử dụng chung các bảng chiều. Khi đó các bảng sự kiện và bảng chiều sẽ tạo ra mối quan hệ giống như một đồ thị – và một hình ảnh rất giống với mối quan hệ này là chòm sao (Figure 3 bên phải).
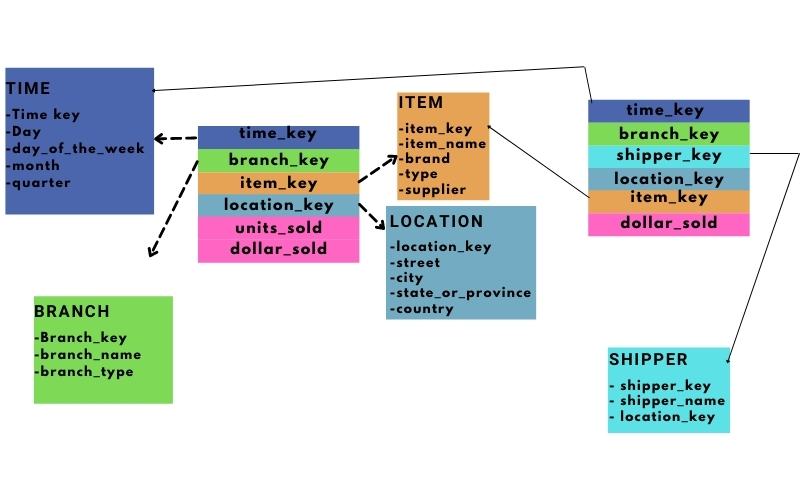
Trong ví dụ ở Figure 4, khi bổ sung thêm vào bảng sự kiện Giao hàng (shipping), khi đó bảng sự kiện này sẽ có nhu cầu sử dụng chiều location, item, time.
Việc sử dụng chung chiều có ưu điểm là rút gọn được số lượng bảng chiều. Nhưng việc làm này sẽ ảnh hưởng lớn đến quá trình ETL dữ liệu. Giả sử hệ thống quản lý bán hàng là tách biệt với hệ thống quản lý giao hàng, khi đó cần phải lấy thông tin từ cả 2 nguồn dữ liệu để đẩy vào bảng chiều chung là location.
Nhược điểm của mô hình chòm sao là phức tạp, khó sử dụng và cần đọc tài liệu hướng dẫn thì mới có thể hiểu và lấy được thông tin cần từ Kho dữ liệu. Các công đoạn khác như ETL cũng sẽ phức tạp hơn so với các mô hình khác. Vì đặc điểm mô hình này phức tạp nên một số sách có thể không đề cập giới thiệu mô hình này.
Với các mô hình biểu diễn sẽ có các ưu điểm và nhược điểm riêng, nên người thiết kế phải chịu trách nhiệm lựa chọn mô hình nào phù hợp.
Nguồn:Internet







